
Generative AI 新世界 | Falcon 40B 大模型微调和量化实践
黄浩文
资深开发者布道师
亚马逊云科技
专注于 AI/ML、Data Science 等。拥有 20 多年电信、移动互联网以及云计算等行业架构设计、技术及创业管理等丰富经验,曾就职于 Microsoft、Sun Microsystems、中国电信等企业,专注为游戏、电商、媒体和广告等企业客户提供 AI/ML、数据分析和企业数字化转型等解决方案咨询服务。
在上一期的文章中,我们一起梳理了大模型参数高效微调(PEFT)和 QLoRA 量化技术背后的理论基础。与标准的 16 位模型微调相比,QLoRA 减少了大模型微调的内存使用量,而无需权衡性能。探索完基本理论之后,我们就要开始动手实践了。
欢迎您加入亚马逊云科技(Amazon Web Services,AWS)!AWS是全球领先的云计算服务提供商,为个人、企业和组织提供稳定、可靠的云服务。通过AWS,您可以轻松构建网站、应用程序、存储数据、进行分析和机器学习等多种应用场景,快速响应业务需求。无论您是初学者还是资深开发者,AWS都能为您提供丰富的学习资源、技术支持和灵活的服务选择。立即注册亚马逊云科技账户,开启云计算之旅,探索无限的可能性!
本期文章,我们将探讨使用 Amazon SageMaker Studio 在交互式环境中,快速高效地微调大语言模型。我们将运用 QLoRA 和 4-bits的bitsandbtyes 量化技术原理,在 Amazon SageMaker Studio 上使用 Hugging Face PEFT 来微调 Falcon-40B 模型。
实践方法概述
Amazon SageMaker 提供了两个选项方法,用于启动完全托管的 notebook,用于探索数据和构建机器学习(ML)模型。
第一种选项是 Amazon SageMaker Studio。这是一个完全集成的机器学习开发环境(IDE),用户可以在 Amazon SageMaker Studio 中快速启动 notebook,在不中断工作的情况下向上或向下伸缩底层计算资源,甚至可以在 notebook 上实时共同编辑和协作。用户可以在 Amazon SageMaker Studio 的单一管理面板中执行所有机器学习开发步骤,包括:构建、训练、调试、跟踪、部署和监控模型等。
第二个选项是 Amazon SageMaker Notebook 实例。这是一个在云端运行 notebook 的完全托管的 ML 计算实例,这个方法可以帮助用户更好地控制 notebook 配置。
本例中我们将使用 Amazon SageMaker Studio。主要选择的原因有两点:
1) 可以利用 SageMaker Studio 的托管 TensorBoard 实验跟踪,以及 Hugging Face Transformer 对 TensorBoard 的支持;
2) Amazon SageMaker Studio 的 Amazon EFS 容量,可以无需预先预置 EBS 卷大小。鉴于 LLM 中模型权重较大,这在实践中很有帮助。
如果你想选择第二个选项,也是可行的。示例代码将同样适用于使用 conda_pytorch_p310 内核的 notebook 实例。
另外,在 Amazon SageMaker Studio 使用完 notebook 实例后,请将其关闭,以避免产生不必要的额外费用。本文最后有删除和清理资源的示例代码,可供参考。
本文的主要参考文档来自以下亚马逊云科技的官方博客。为阐述清楚其中的细节,本文增加了较多的章节扩展分析和代码对照的讲解:
模型微调过程的拆解分析
1.启动 Amazon SageMaker JumpStart 环境
本实验的完整示例代码可参考:
示例代码的 notebook 在 Amazon SageMaker Studio 测试通过,内核为 Python 3(Data Science 3.0),实例为一台 ml.g5.12xlarge 实例。
2.安装模型微调所需的库
首先,安装所需的库,包括 Hugging Face 库,然后重新启动内核。
1 | %pip install -q -U torch==2.0.1 bitsandbytes==0.40.2 |
我自己环境的 cuda_install_dir 路径如下输出所示:

3.输入文本的 Tokenizer 和大模型的量化
要训练模型,我们需要将输入文本转换为 token ID,这个工作可以交给 Hugging Face Transformers Tokenizer 完成。除了 QLoRA 之外,我们还将使用 bitsandbytes 的 4 位精度方法将 LLM 量化为 4 位,并遵照在上篇文章中介绍过的 QLoRA 论文中阐述的方法,在量化后的 LLM 上面配接 LoRA adapter。
1 | import torch |


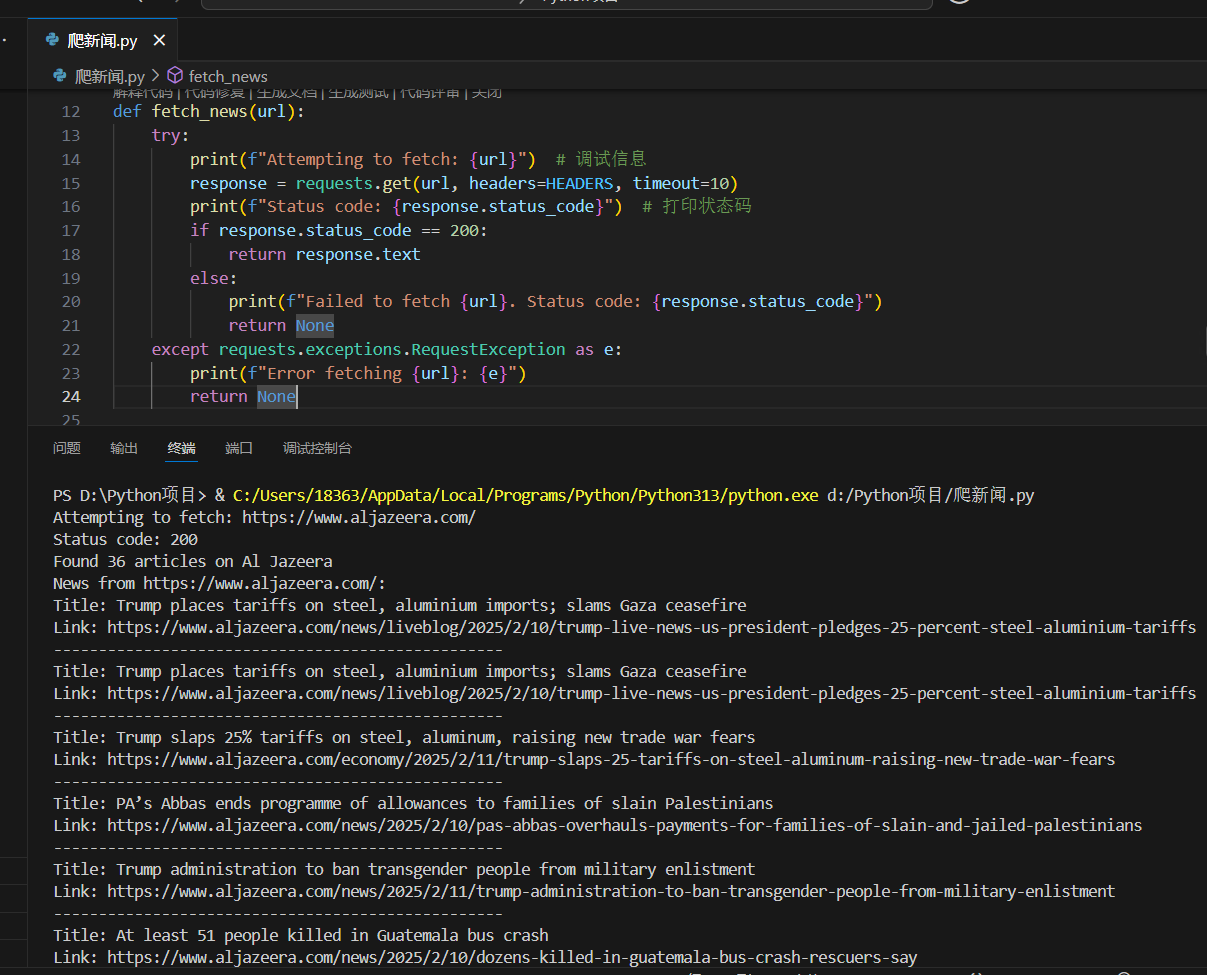
这个 Falcon 40B LLM 量化到 4-bit 精度的过程,我自己实测大约需要用时 5 分钟左右。如上图所示。
另外,我们还需要设置代表句子结尾的特殊标记,如下图输出的 “|endoftext|”,就是代表句子结尾的特殊标记。关于 Tokenizer 的设置详情,可参考 Tokenizer的类说明文档。
1 | # Set the Falcon tokenizer |
输出如下图所示:

4.为 LoRA 微调训练方法准备模型
接下来要开始为 PEFT 工作准备模型了。
1 | from peft import prepare_model_for_kbit_training |

定义打印模型中可训练参数的函数:
1 | def print_trainable_parameters(model): |
使用 PEFT 为 LoRA 微调训练方法准备模型和 LoRA 参数配置细节:
1 | model, preprocess = clip.load("ViT-B/32") |
注意看输出的最后一行,即可训练参数的数量:

由以上输出可见,所有参数数量是 209 亿以上,可训练参数数量是 5500 万,只占全部参数的 0.26%。由于训练参数的大幅减少,可预计的训练时间也会大大缩短。
5.加载微调模型的数据集
要加载 samsum 数据集,我们使用 Hugging Face 数据集库中的 load_dataset () 方法。
1 | from datasets import load_dataset |
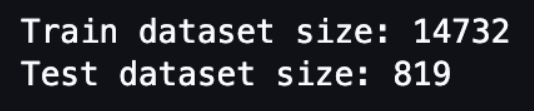
由以上输出可见,这个数据集并不大。训练数据 14732 条,测试数据 819 条。
接下来,我们需要创建提示词模板,并使用随机样本加载数据集做汇总测试。
1 | from random import randint |
提示词模版示例输出如下图所示。
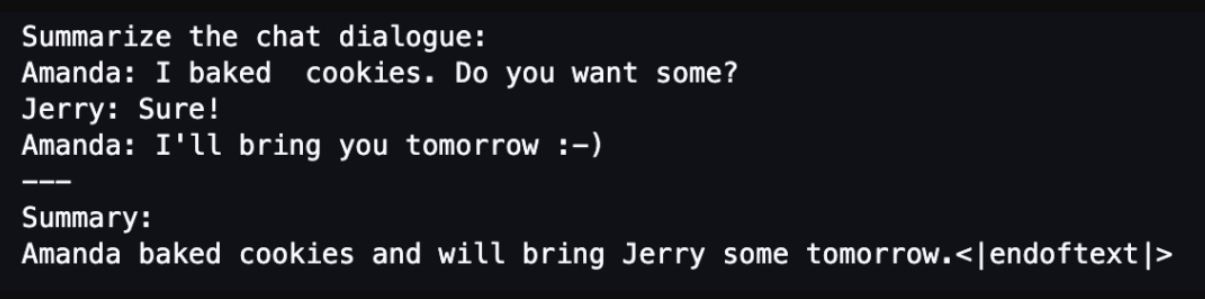
以下代码将提示词模版应用到每一个 sample 里:
1 | # apply prompt template per sample |
对数据集做 tokenize 和 chunk:
1 | # tokenize and chunk dataset |

为了完成实时监控的任务,我们首先需要把训练过程的各项指标记录下来,比如:用一个 S3 桶来存放记录。因此,我们还需要为这个实验创建一个 S3 桶,以方便我们将训练中的各项指标完整地记录到 TensorBoard:
1 | # bucket = <YOUR-S3-BUCKET> |
如果你试着打印 log_bucket 的输出,将类似是如下这样的,它定义了一个 S3 桶:
1 | 's3://llm-demo-xxxxxx/falcon-40b-qlora-finetune' |
6.微调训练过程指标的记录
然后将使用 Hugging Face Trainer 类对模型进行微调,定义要使用的超参数。我们还创建了一个 DataCollator 来填充我们的输入和标签。另外,因为要考虑做模型微调训练过程的监测,可以通过定义参数 logging_dir 和设置report_to=”tensorboard”,来请求 Hugging Face Transformer 把微调训练的日志记录到 TensorBoard。
1 | import transformers |
完成以上配置,就可以开始正式启动微调的训练了。启动的代码很简单,如下所示:
1 | # Start training |
模型微调监控的拆解分析
1.实时监控 GPU 使用情况
前面的设置完成后,我们就可以实时监控微调过程了。为了实时监控 GPU 使用情况,我们可以直接从内核的容器运行 nvidia-smi 命令。要启动在镜像容器上运行的终端,只需选择笔记本顶部的终端图标即可。

我们可以使用 Linux watch 命令每半秒钟重复运行 nvidia-smi:
1 | watch -n 0.5 nvidia-smi |
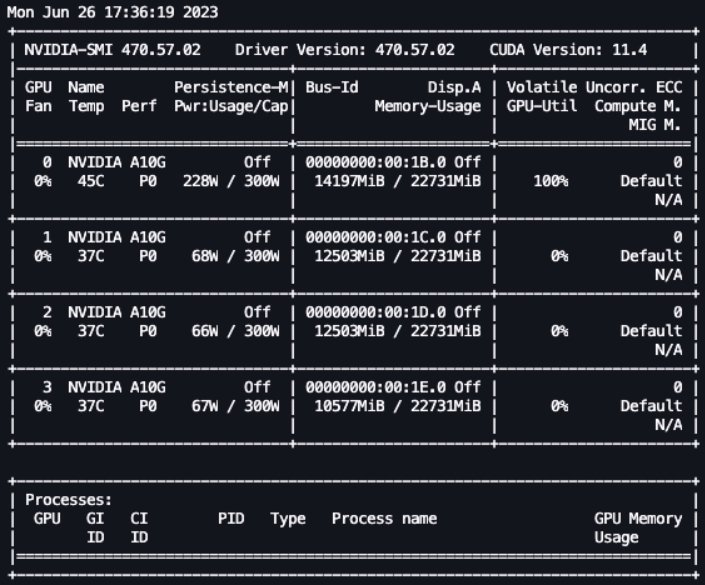
在上面的动图中,我们可以看到模型权重分布在 4 个 GPU 上,随着层的串行处理,计算负载在这些 GPU 之间做分布计算。
2.实时监控模型微调的训练指标
为了监控模型微调过程中的训练指标,我们将把 TensorBoard 日志写入之前已经配置好的 S3 桶。可以从 SageMaker 控制台启动 SageMaker Studio 域用户的 TensorBoard,如下截图所示:
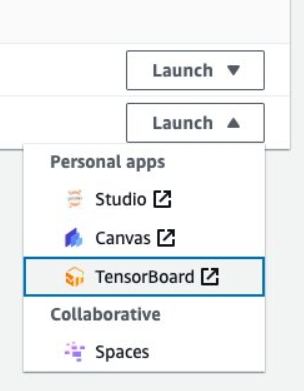
TensorBoard 加载完成后,可以指定 Hugging Face transformer 把训练日志写入指定的 S3 桶,以便查看训练和评估指标,如下图所示。

以上配置完成后,就可以通过 TensorBoard 的 “Time Series” 菜单,监控微调模型训练过程中各项指标随着训练时间的变化,包括:回合(epoch)、学习率(learning rate)、损失函数(loss)等等。
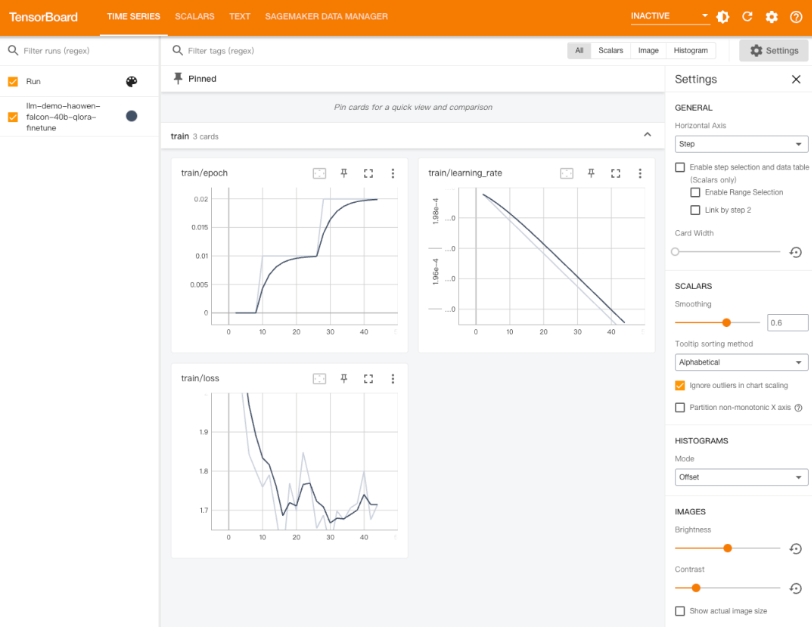
模型微调后的评估和生成结果
模型完成微调训练后,我们就可以对微调后的大模型进行系统评估或直接生成结果了。由于模型的评估又是另一个宏大的话题,本文会暂时略过这个话题,留待以后专题讨论;本文之后将主要聚焦微调后模型的结果生成示例。
首先,加载之前分拆出来的 samsum 测试数据集,并尝试使用随机样本进行 LLM 总结(Summary)测试:
1 | # Load dataset from the hub |
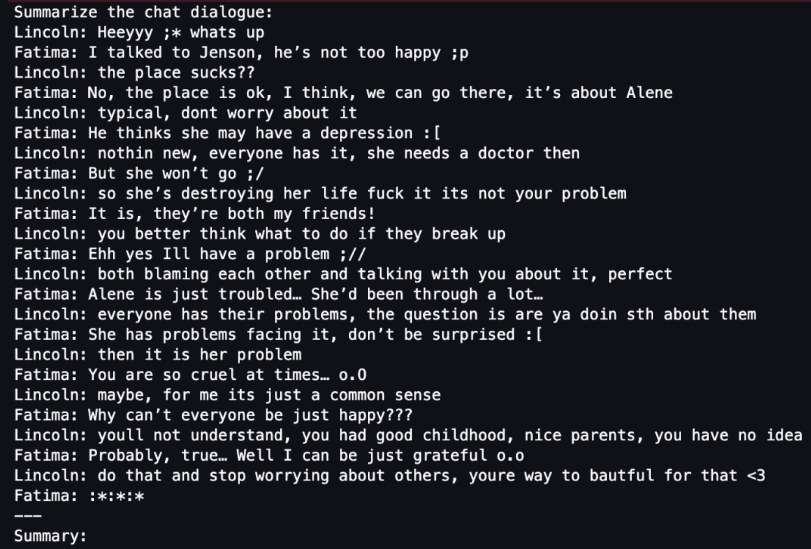
接下来,把输入数据 tokenizer 化:
1 | input_ids = tokenizer(test_sample, return_tensors="pt").input_ids |
把 tokenizer 化后的输入数据传给微调后的 LLM,获取 LLM 总结(Summary)的输出结果:
1 | #set the tokens for the summary evaluation |
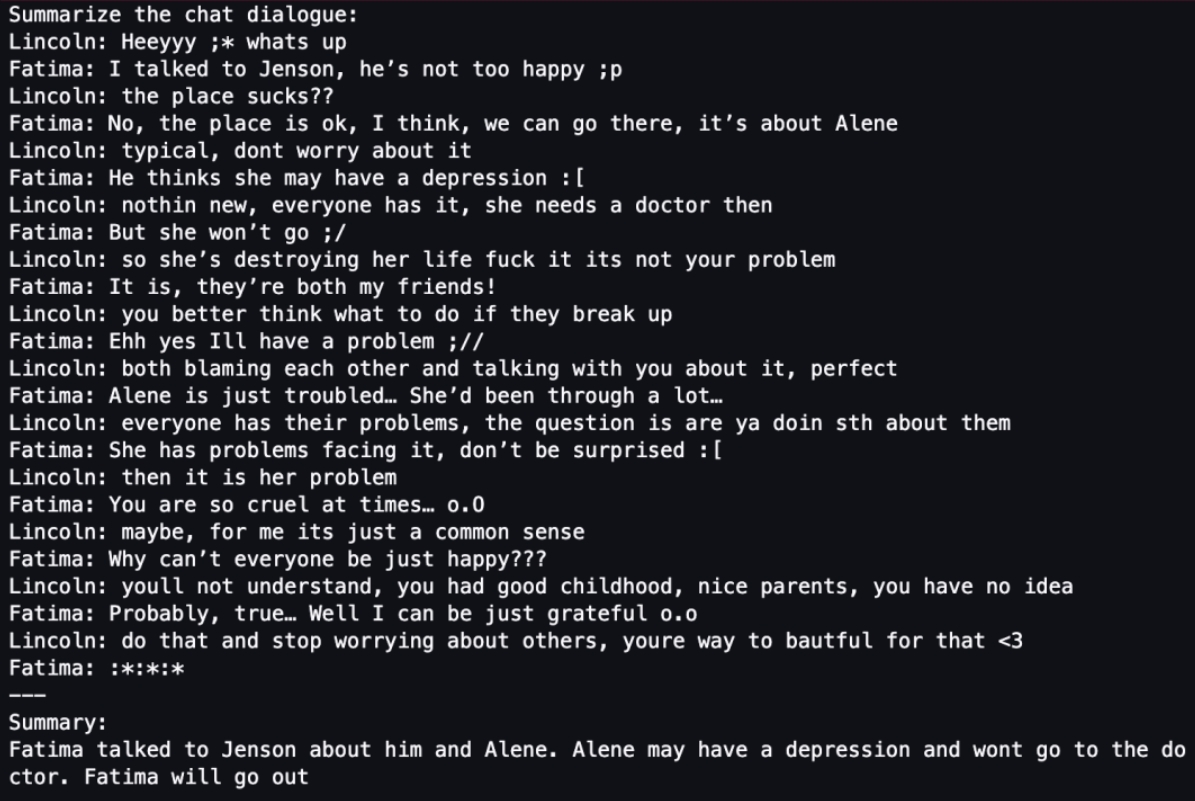
有心的同学,可以通过模型微调前后,LLM 输出的总结(Summary)结果比较,来对比微调后的模型,是否在准确性和完整性上有了一定的改善。
如果你对模型的性能感到满意,可以把模型保存下来,如下代码所示:
1 | trainer.save_model("path_to_save") |
或者把模型部署到一个专门的 SageMaker 终端节点。部署终端节点的文档可参考:
资源的删除和清理
实验完成后,请记得删除和清理资源,以避免不必要的额外费用。需要清理的资源分为三个部分,如下所示:
1)关闭 SageMaker Studio 实例
https://docs.aws.amazon.com/sagemaker/latest/dg/notebooks-run-and-manage-shut-down.html
2)关闭你的 TensorBoard 应用程序
3)清除 Hugging Face 缓存目录,参考命令如下所示:
1 | rm -R ~/.cache/huggingface/hub |
总结
在本文中,我们探讨了使用 Amazon SageMaker Studio在交互式环境中,快速高效地微调 Falcon 40B 大语言模型。我们运用了 QLoRA和 4-bits 的 bitsandbtyes 量化技术原理,在 Amazon SageMaker Studio 上使用 Hugging Face PEFT 微调了 Falcon-40B 模型。
本文做为 “Generative AI 新世界”的第十二篇文章,在不知不觉中已经伴随着各位热爱生成式 AI 领域知识的读者们,从初春走到了盛夏。随着我们一起对生成式 AI 知识的逐步深入学习,这个系列后面的文章内容会往更深度的专业领域做拓展。
目前计划有三个大方向:
1)代码深度实践方向。例如用代码完整诠释 Diffusion 模型的工作原理,或者 Transformer 的完整架构等;
2)模型部署和训练优化方向。例如尝试解读 LMI、DeepSpeed、Accelerate、FlashAttention 等不同模型优化方向的最新进展;
3)模型量化实践方向。例如 GPTQ、bitsandbtyes 等前沿模型量化原理和实践等。敬请期待。
关注亚马逊云科技官网,了解更多面向开发者的技术分享和云开发动态!
前述特定亚马逊云科技生成式人工智能相关的服务仅在亚马逊云科技海外区域可用,亚马逊云科技中国仅为帮助您了解行业前沿技术和发展海外业务选择推介该服务。



Ctrl+D 收藏本站吧
找工作,来万马优才
Peptide Synthesis





{kind=link}