背景
静态页面通常由HTML、CSS 和 JavaScript 等静态文件组成,这些文件在服务器上不会动态生成或修改,所以加载速度通常比较快。也利于搜索引擎的抓取,适合用于展示固定内容的网站,如企业官方网站、产品介绍页、博客文章等。
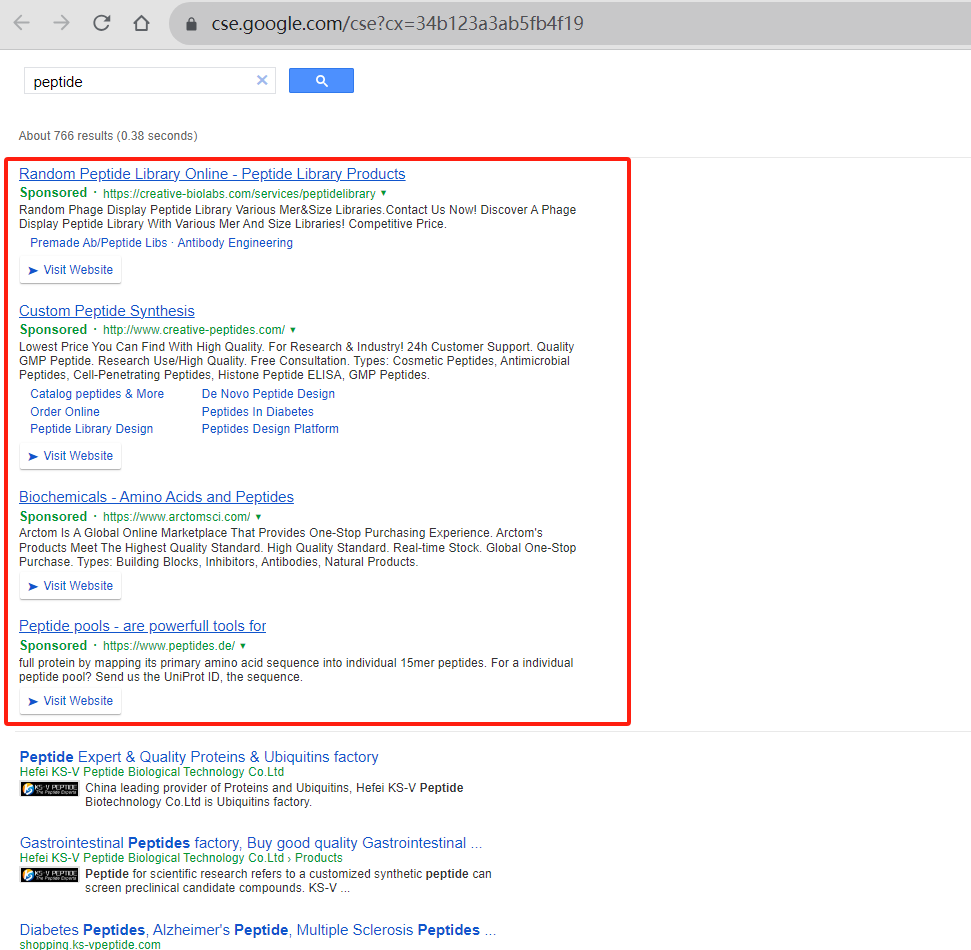
为网页添加搜索模块的第三方网站有不少,首先我尝试了一下谷歌的站内搜索,让人比较痛苦的一个是前几行都是谷歌广告,而且还去不掉,还有一点就是搜索结果只能展示谷歌收录的页面,比如我网站加上小语种至少有几千个页面了,但是谷歌实际收录的页面只有几百,也就是说百分之80-90的结果都展示不出来,这两点就让人很绝望了,不得不另谋他路。
解决方案
从网上摸索了一圈,终于找到了一种比较简单的使用 js 实现的搜索功能,经过几番倒腾终于可以成功复现。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
| <!DOCTYPE html>
<html lang="en">
<head>
<meta charset="UTF-8">
<meta name="viewport" content="width=device-width, initial-scale=1.0">
<title>Search Example</title>
<style>
#searchInput {
margin-bottom: 10px;
}
.urlset li {
display: none;
}
.pagination {
margin-top: 10px;
}
</style>
</head>
<body>
<input type="text" id="searchInput" placeholder="输入关键字">
<ul class="urlset">
<li class="aurl"><a href="https://www.ks-vpeptide.com/" data-lastfrom="" title="Peptide Expert & Quality Proteins & Ubiquitins factory">Peptide Expert & Quality Proteins & Ubiquitins factory</a></li>
<li class="aurl"><a href="https://www.ks-vpeptide.com/webim/webim_tab.html" data-lastfrom="" title="chat with us">chat with us</a></li>
<li class="aurl"><a href="https://www.ks-vpeptide.com/aboutus.html" data-lastfrom="" title="China Hefei KS-V Peptide Biological Technology Co.Ltd company profile">China Hefei KS-V Peptide Biological Technology Co.Ltd company profile</a></li>
</ul>
<script>
document.getElementById('searchInput').addEventListener('input', function () {
var searchKeyword = this.value.toLowerCase();
var links = document.querySelectorAll('.urlset a');
links.forEach(function (link) {
var title = link.getAttribute('title').toLowerCase();
var url = link.getAttribute('href').toLowerCase();
if (title.includes(searchKeyword) || url.includes(searchKeyword)) {
link.parentNode.style.display = 'block';
} else {
link.parentNode.style.display = 'none';
}
});
});
</script>
</body>
</html>
|
效果如下:
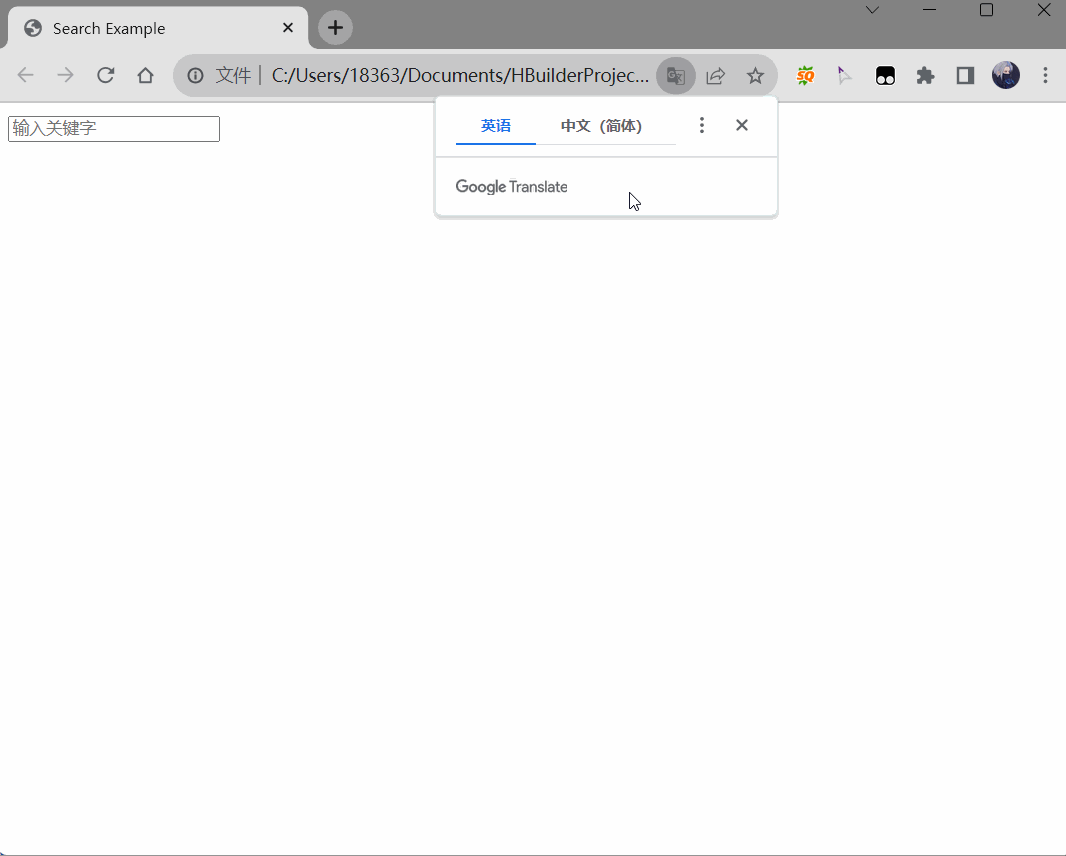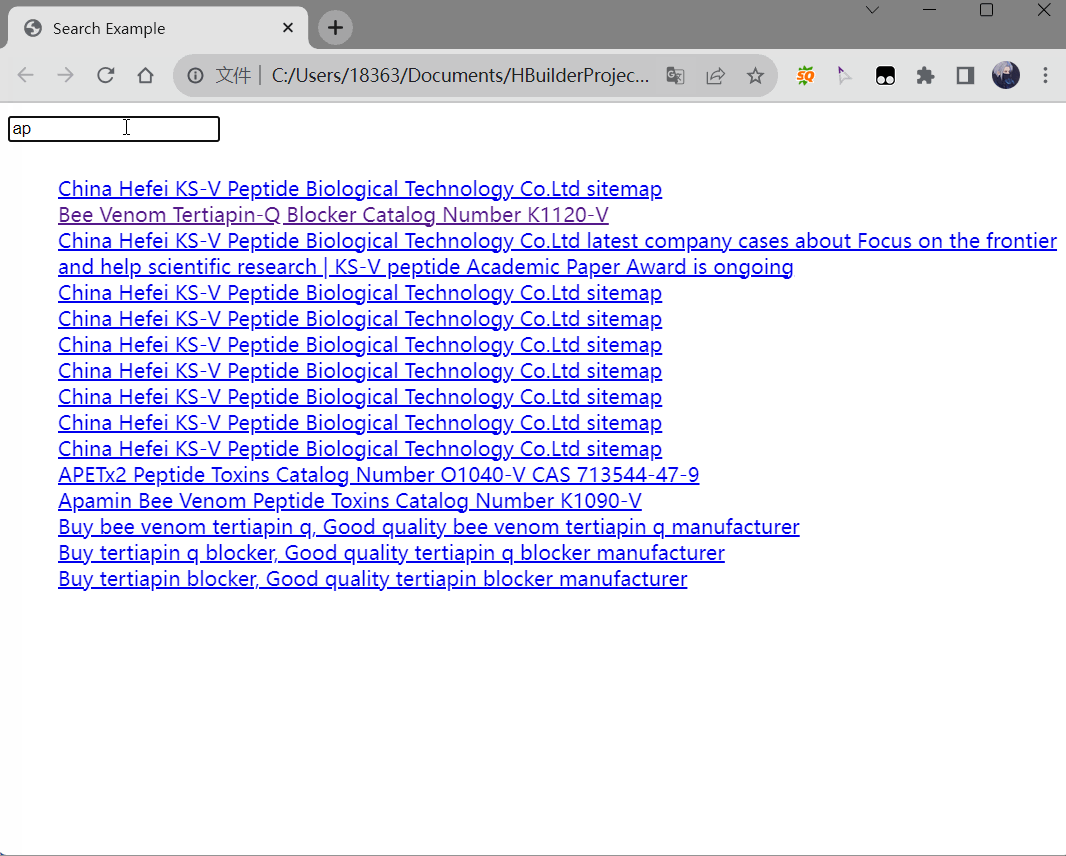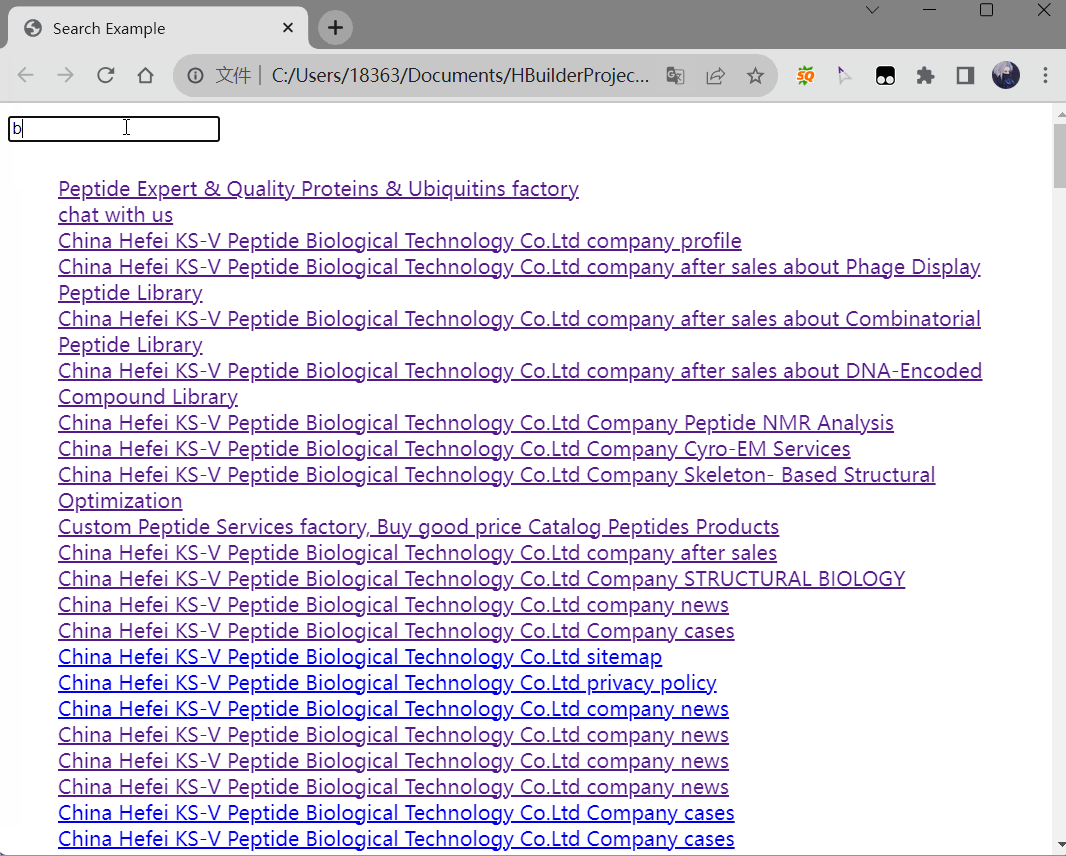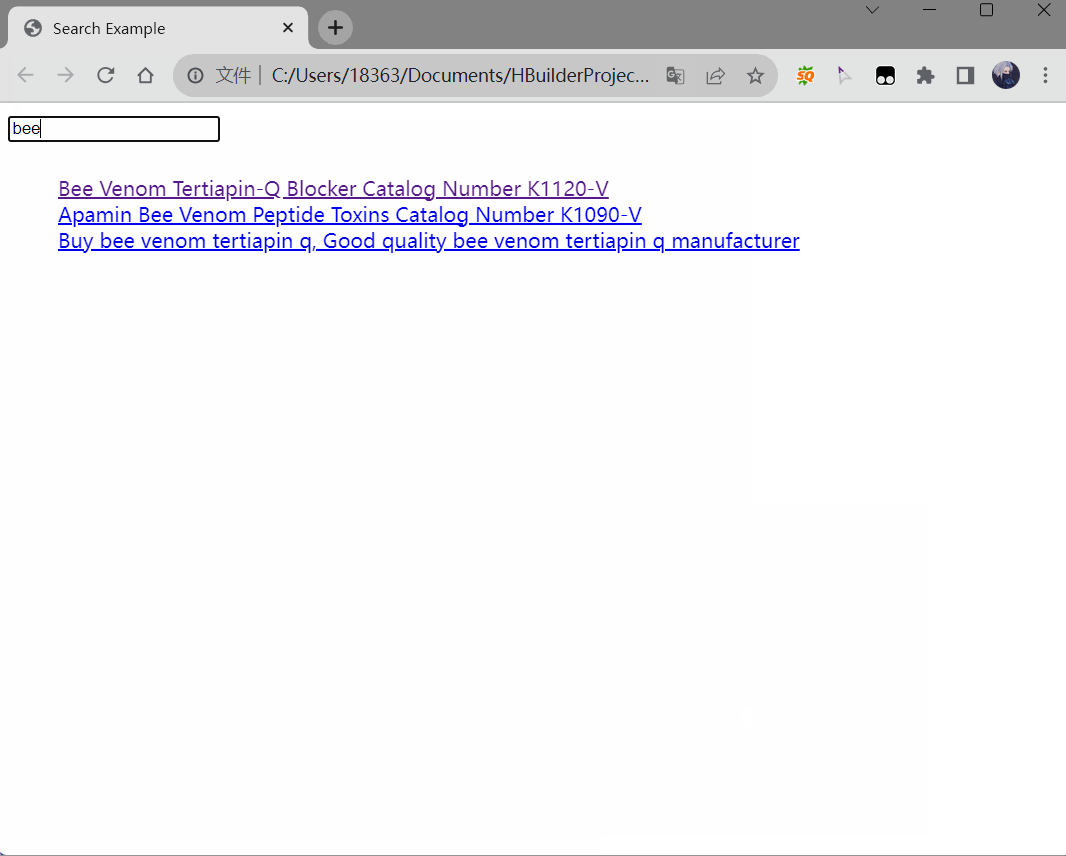
到这里我们已经初步完成了一个简陋的搜索功能,页面不多的个人博客、小型企业站其实已经可以拿来用了。但是当我们页面比较多,比如有300+页面,那么上面光一个搜索功能就需要接近400行的代码,每个页面都放入这400行代码,直接300*400,加重服务器的负担,影响页面加载速度,维护起来也十分困难。
优化方法
首先我们将这些链接+标题都放入一个xml中,格式如下:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
| <?xml version="1.0" encoding="UTF-8"?>
<links>
<link>
<url>https://www.ks-vpeptide.com/</url>
<title>Peptide Expert & Quality Proteins & Ubiquitins factory</title>
</link>
<link>
<url>https://www.ks-vpeptide.com/webim/webim_tab.html</url>
<title>chat with us</title>
</link>
<link>
<url>https://www.ks-vpeptide.com/aboutus.html</url>
<title>China Hefei KS-V Peptide Biological Technology Co.Ltd company profile</title>
</link>
<link>
<url>https://www.ks-vpeptide.com/buy-h4k12ac.html</url>
<title>Buy h4k12ac, Good quality h4k12ac manufacturer</title>
</link>
<link>
<url>https://www.ks-vpeptide.com/contactnow.html</url>
<title>Send your inquiry directly to us</title>
</link>
</links>
|
页面较多的可以用工具生成xml,我这保存了一个可以免费生成网站站点地图的工具:https://sitemap.zhetao.com/

该工具有一点较好的是它生成的格式有多种供选择,缺点就是一个站点180天只能生成一次,挺难受的。
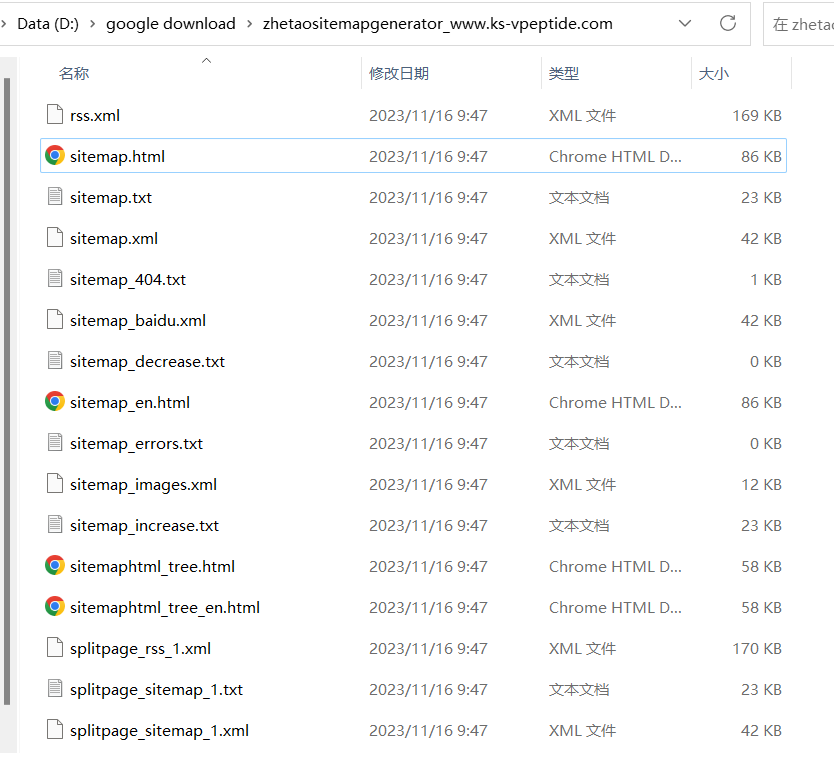
到这里我们把之前的代码修改一下,
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
| <body>
<input type="text" id="searchInput" placeholder="输入关键字">
<ul class="urlset">
</ul>
<script>
document.getElementById('searchInput').addEventListener('input', function () {
var searchKeyword = this.value.toLowerCase();
<!-- your_links.xml 换成你的 xml 名称 -->
fetch('your_links.xml')
.then(response => response.text())
.then(data => {
var parser = new DOMParser();
var xmlDoc = parser.parseFromString(data, 'application/xml');
var links = xmlDoc.querySelectorAll('link');
links.forEach(function (link) {
var url = link.querySelector('url').textContent.toLowerCase();
var title = link.querySelector('title').textContent.toLowerCase();
var li = document.createElement('li');
li.className = 'aurl';
li.innerHTML = `<a href="${url}" data-lastfrom="" title="${title}">${title}</a>`;
document.querySelector('.urlset').appendChild(li);
if (title.includes(searchKeyword) || url.includes(searchKeyword)) {
li.style.display = 'block';
} else {
li.style.display = 'none';
}
});
})
.catch(error => console.error('Error fetching XML:', error));
});
</script>
</body>
|
改完之后我发现搜索结果出不来了,看了下控制台的报错,原来是浏览器的同源策略导致的,该策略要求网页中使用的所有脚本(包括 JavaScript、CSS、图片等)都必须来自同一源(协议、域名和端口)。
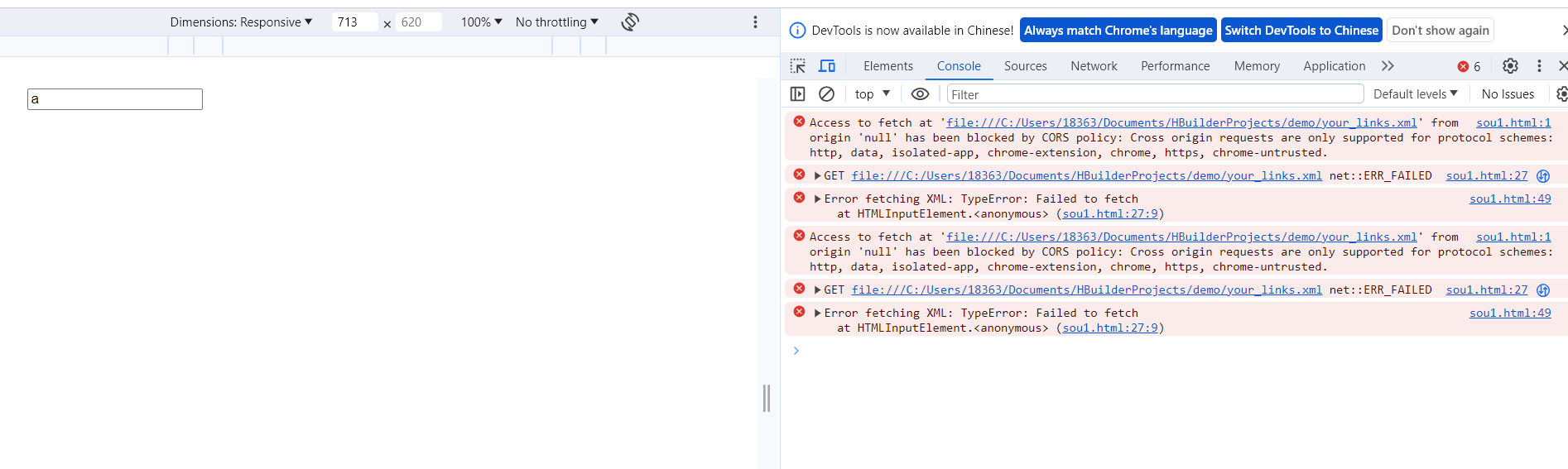
在这种情况下,我的页面是通过 file:/// 协议打开的,而 XML 文件路径是绝对路径 C:/Users/18363/Documents/HBuilderProjects/demo/your links.xml。这导致了跨源请求,因为 file:/// 协议和 C: 协议不同。
解决方法:将文件上传至服务器中运行。试了一下果然好了
在加入我们网站时我们需要将搜索结果置于页面顶层(指的是里外的最外层),所以还需要再加一段CSS,最终完整代码如下:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
90
91
| <!DOCTYPE html>
<html lang="en">
<head>
<meta charset="UTF-8">
<meta name="viewport" content="width=device-width, initial-scale=1.0">
<title>Search Example</title>
<style>
#searchInput {
margin-bottom: 10px;
}
.searchResults {
position: absolute;
top: 60px;
left: 10px;
z-index: 999;
background-color: white;
border: 1px solid #ccc;
padding: 10px;
display: none;
}
.searchResults li {
list-style-type: none;
}
</style>
</head>
<body>
<form>
<input type="text" id="searchInput" placeholder="Search Keywords or Catalog Number">
</form>
<ul class="searchResults">
</ul>
<script>
const searchInput = document.getElementById('searchInput');
const searchResultsContainer = document.querySelector('.searchResults');
searchInput.addEventListener('input', function () {
const searchKeyword = this.value.toLowerCase();
searchResultsContainer.innerHTML = '';
if (searchKeyword.trim() === '') {
searchResultsContainer.style.display = 'none';
return;
}
fetch('https://ks-vpeptide.haiyong.site/your_links.xml')
.then(response => response.text())
.then(data => {
const parser = new DOMParser();
const xmlDoc = parser.parseFromString(data, 'application/xml');
const links = xmlDoc.querySelectorAll('link');
let hasResults = false;
links.forEach(link => {
const url = link.querySelector('url').textContent.toLowerCase();
const title = link.querySelector('title').textContent.toLowerCase();
if (title.includes(searchKeyword) || url.includes(searchKeyword)) {
const li = document.createElement('li');
li.className = 'aurl';
li.innerHTML = `<a href="${url}" data-lastfrom="" title="${title}">${title}</a>`;
searchResultsContainer.appendChild(li);
hasResults = true;
}
});
searchResultsContainer.style.display = hasResults ? 'block' : 'none';
})
.catch(error => console.error('Error fetching XML:', error));
});
searchInput.addEventListener('blur', function () {
setTimeout(() => {
searchResultsContainer.style.display = 'none';
}, 200);
});
</script>
|
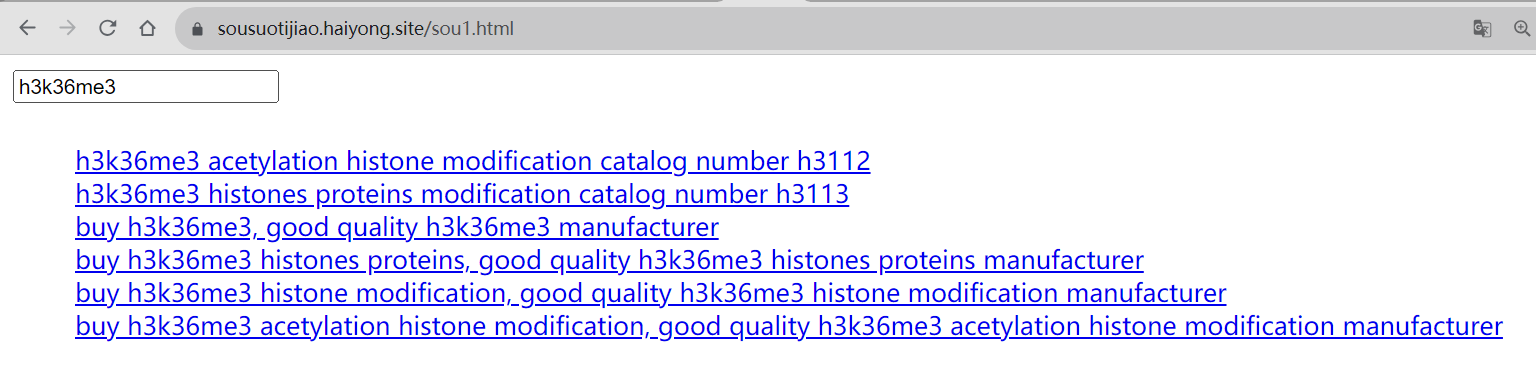
最终实现效果:
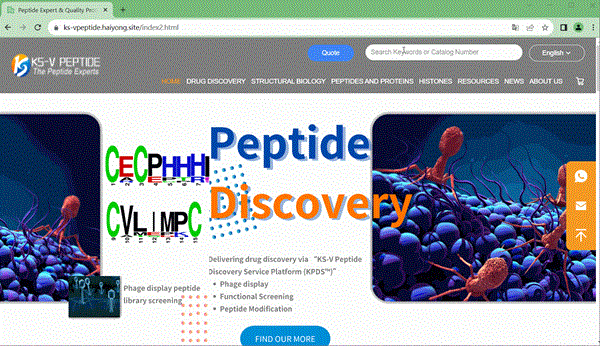
样式还有点奇怪,还需要再调整一下,其他没什么问题了,如果大家有需要帮助,可以在下方评论区告诉我,有什么其他添加搜索功能的好办法也可以分享出来给大家参考。
总结
本文介绍了静态页面添加搜索功能的问题、解决方案和优化方法,通过实例演示了如何利用 JavaScript 动态加载 XML 中的数据实现搜索功能,为需要在静态页面中添加搜索功能的读者提供了一定价值的参考。










{kind=link}