最近有同事问我能不能帮他从 pubmed 网站上批量爬取一些邮箱,上面有些可能是我们的潜在客户,我就开始尝试了一下,首先我们选择其中一个关键词 h3k56 进行搜索,得到228个结果(文章)。
爬取文章链接
往下翻可以看到每个页面只有十个链接,并且是遵循着规律的
1 base_url = "https://pubmed.ncbi.nlm.nih.gov/?term=h3k56&page="
总文章数是228,每页10篇,共23个页面
1 2 total_pages = 23 # 总共的页面数 article_links = [] # 存储文章链接的列表
我们新建一个 pubmed-wenzhang.py,完整代码如下:
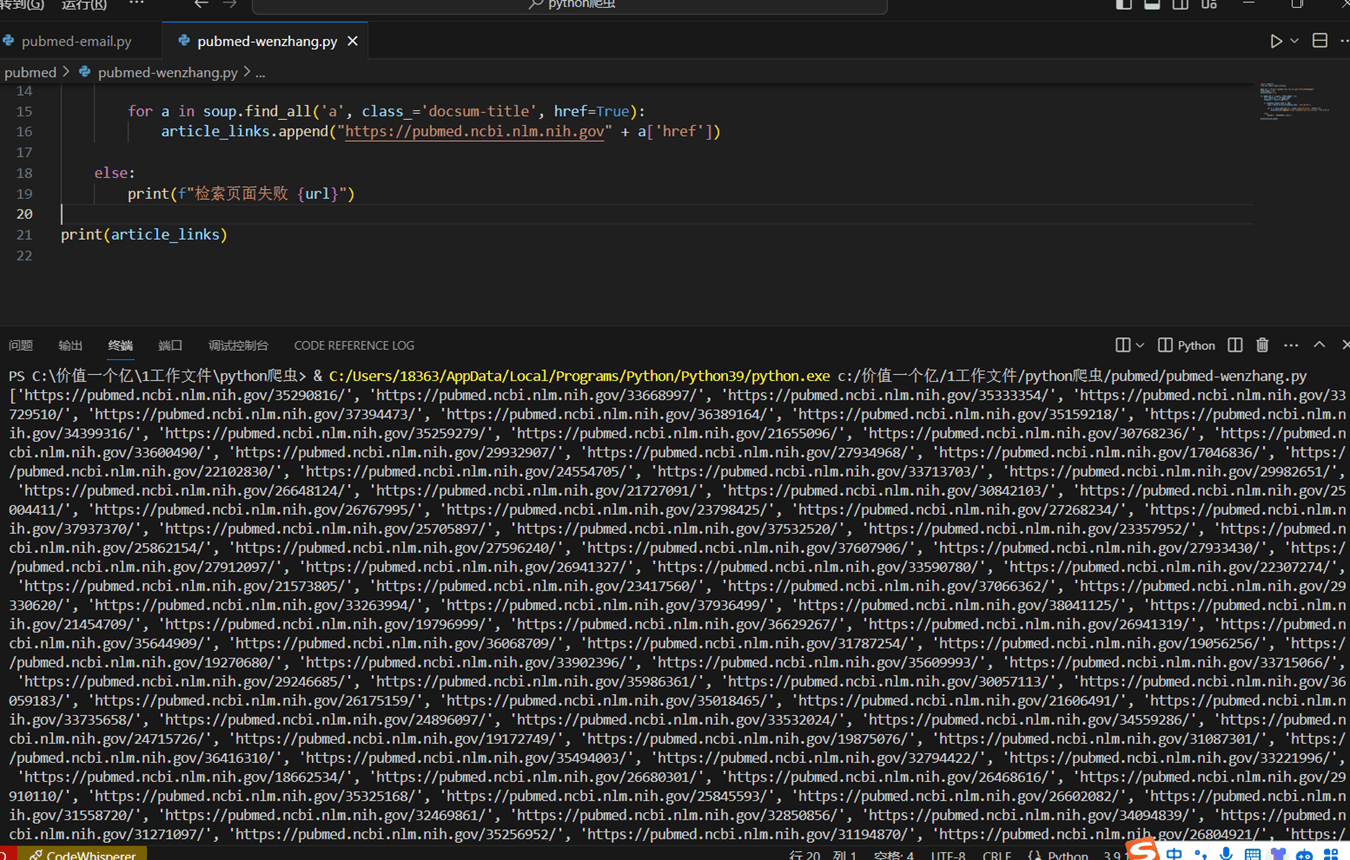
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 import requests from bs4 import BeautifulSoup base_url = "https://pubmed.ncbi.nlm.nih.gov/?term=h3k56&page=" # PubMed搜索基础URL,搜索关键词'h3k56' total_pages = 23 # 总共的页面数 article_links = [] # 存储文章链接的列表 for page_num in range(1 , total_pages + 1 ): url = base_url + str(page_num) # 构建当前页面的完整URL response = requests.get(url) # 发起GET请求获取页面内容 if response.status_code == 200 : # 如果响应码为200 ,表示请求成功 soup = BeautifulSoup(response.text, 'html.parser' ) # 使用BeautifulSoup解析页面内容 for a in soup.find_all('a' , class_='docsum-title' , href=True): # 查找具有'docsum-title' 类的<a>标签 article_links.append("https://pubmed.ncbi.nlm.nih.gov" + a['href' ]) # 将找到的文章链接添加到列表中 else : print(f"检索页面失败 {url}" ) # 请求失败时输出错误信息 print(article_links) # 打印所有文章链接列表
运行程序,大概等待了半分钟,完整输出了 228 篇文章的链接。
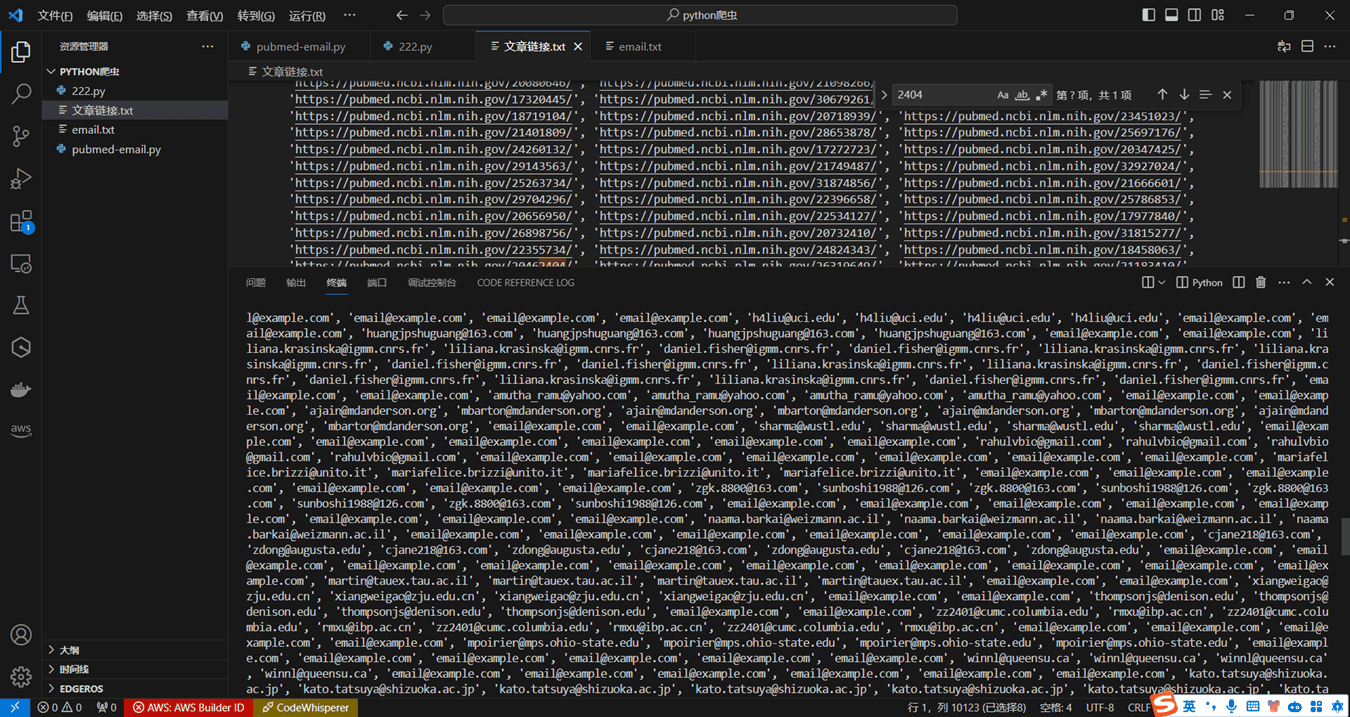
爬取邮箱 这里我们使用Selenium库来模拟浏览器操作,打开每个文章链接页面并提取页面中的邮箱地址,最后将提取到的邮箱地址打印出来。
导入所需的库 1 2 3 from selenium import webdriverimport reimport time
要爬取的文章链接列表 1 article_links = ['https://pubmed.ncbi.nlm.nih.gov/35290816/' , 'https://pubmed.ncbi.nlm.nih.gov/33668997/' , ...]
存储提取到的邮箱地址 设置ChromeOptions 1 2 chrome_options = webdriver.ChromeOptions() chrome_options.binary_location = "C:\\Program Files\\Google\\Chrome\\Application\\chrome.exe"
完整代码如下:
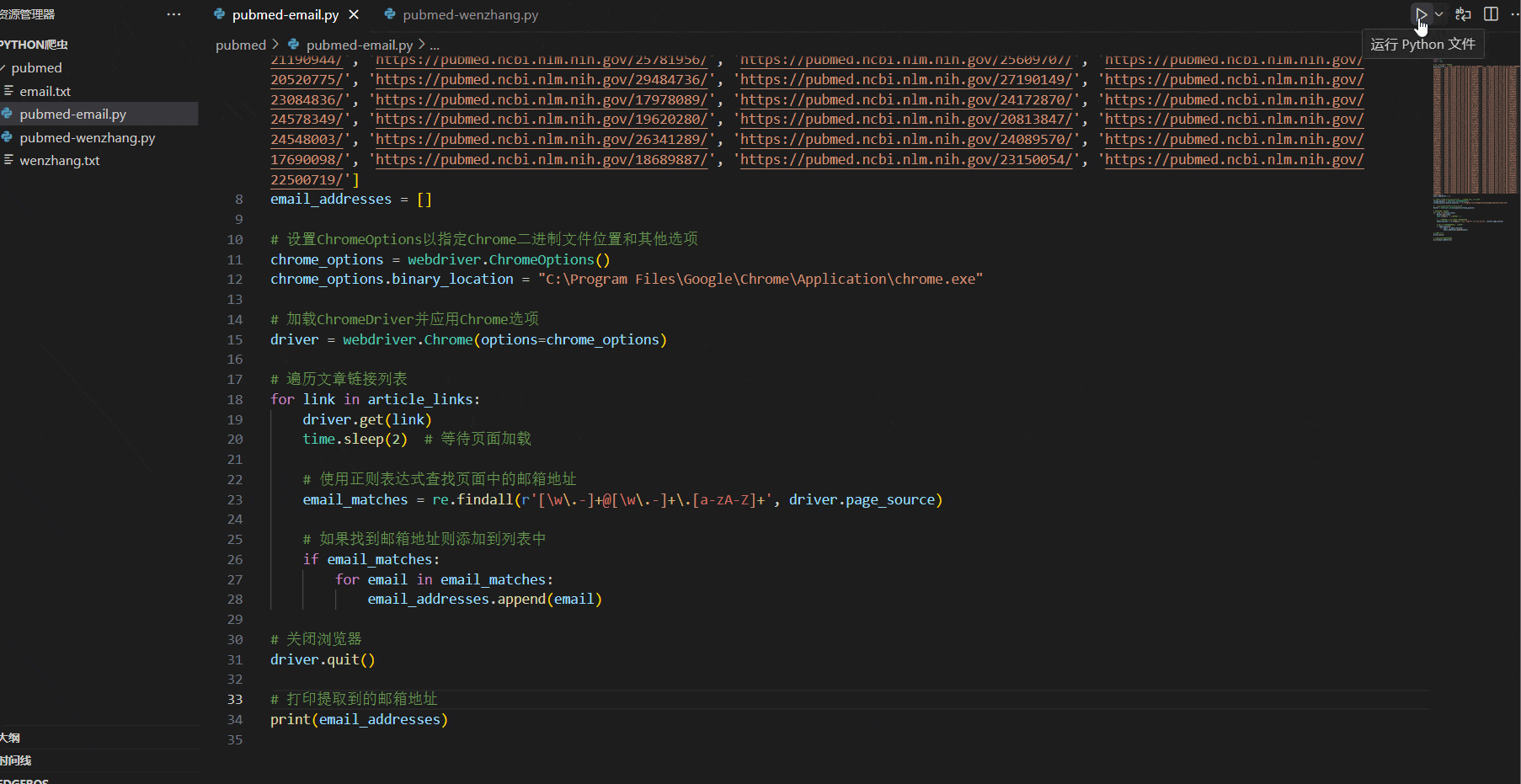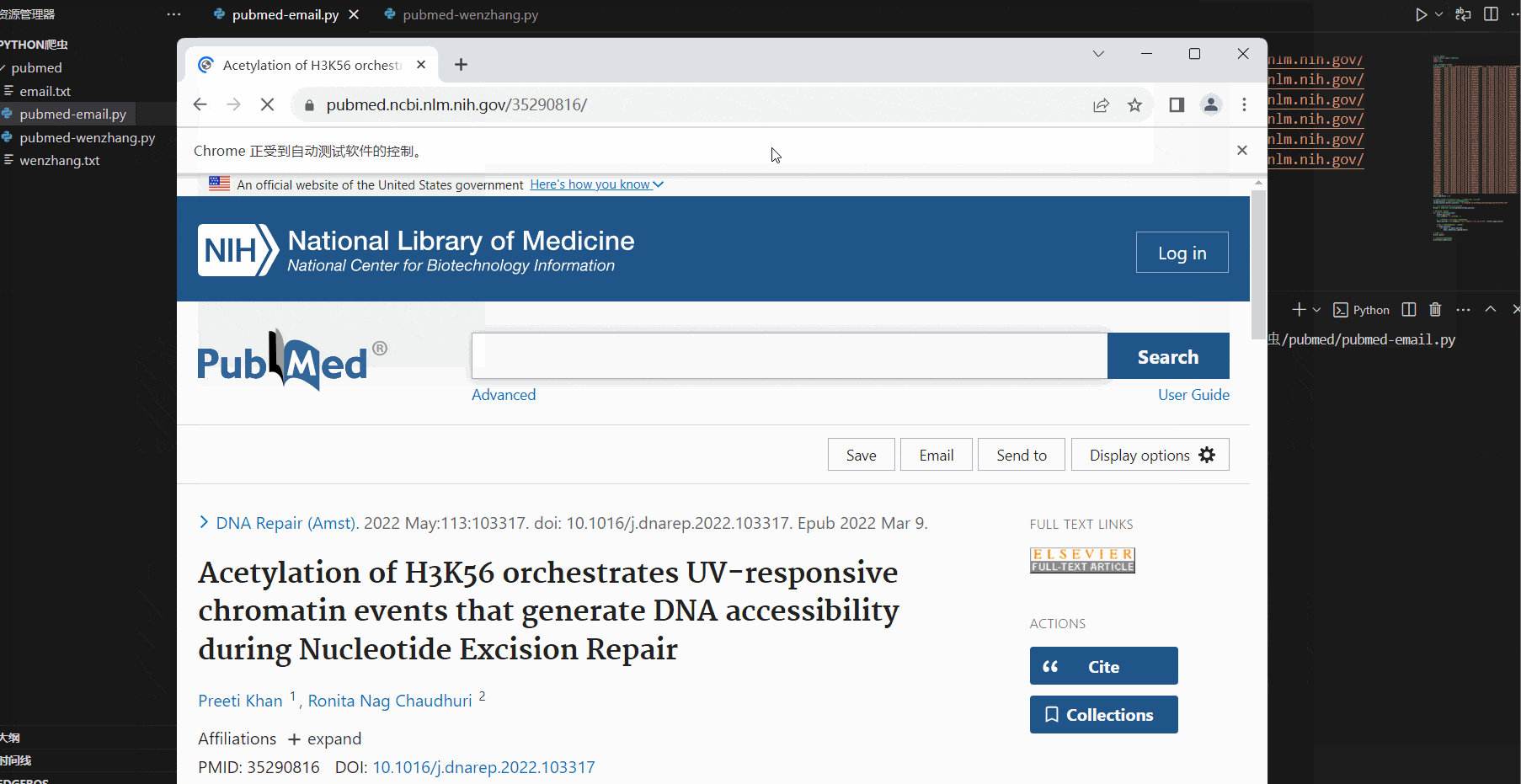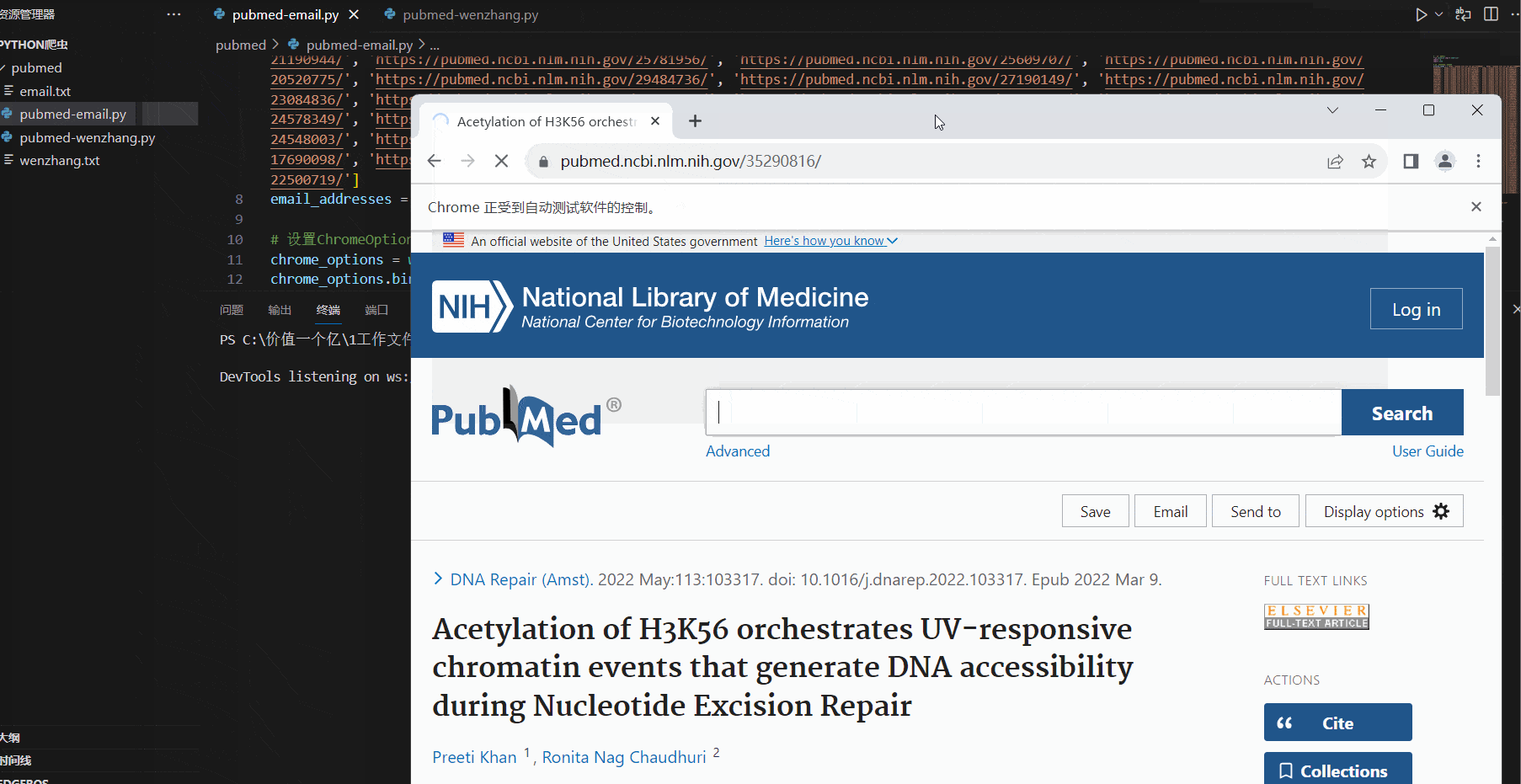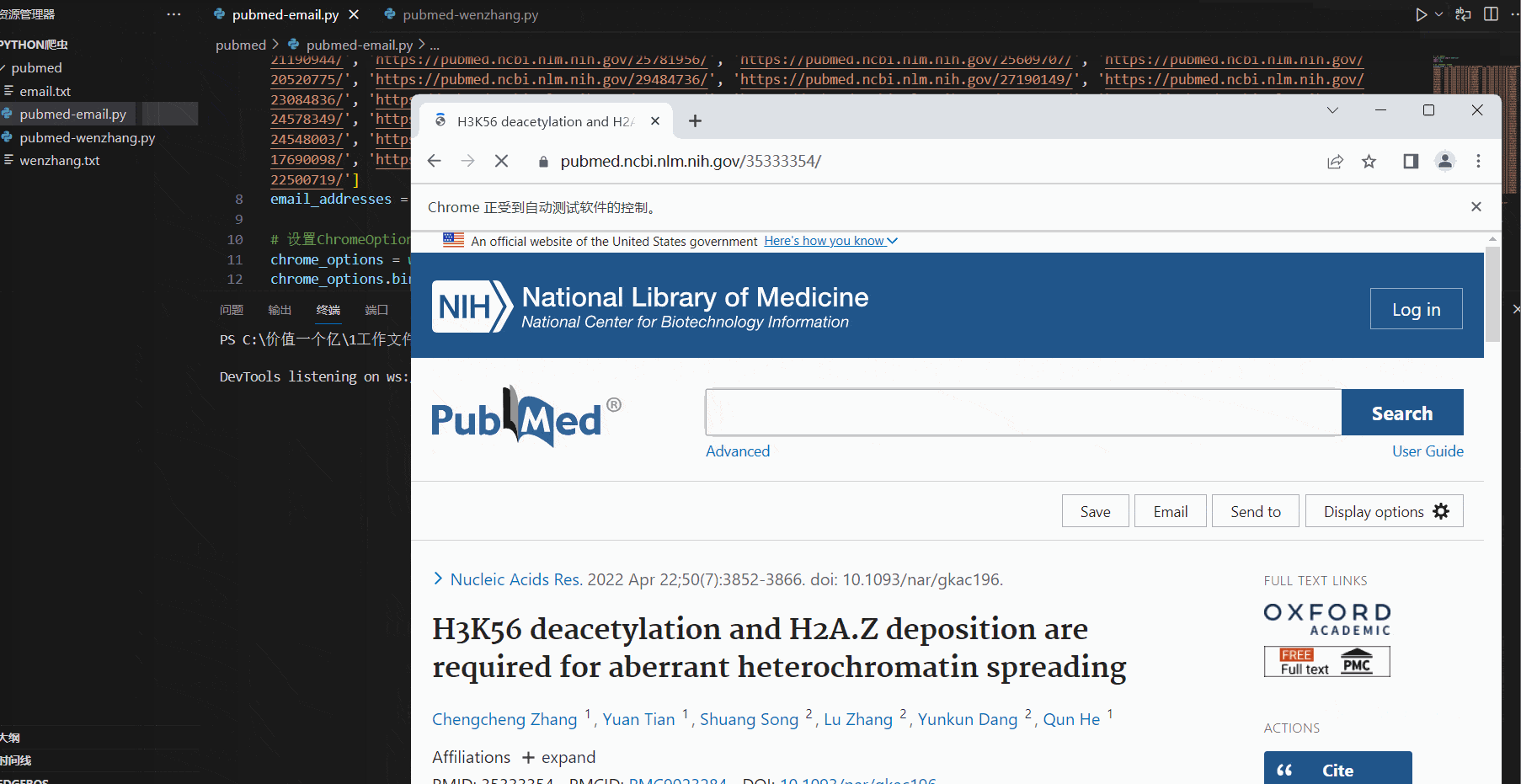
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 from selenium import webdriverimport reimport timearticle_links = ['https://pubmed.ncbi.nlm.nih.gov/35290816/' , 'https://pubmed.ncbi.nlm.nih.gov/33668997/' , ...] email_addresses = [] chrome_options = webdriver.ChromeOptions() chrome_options.binary_location = "C:\\Program Files\\Google\\Chrome\\Application\\chrome.exe" driver = webdriver.Chrome(options=chrome_options) for link in article_links: driver.get(link) time.sleep(2 ) email_matches = re.findall(r'[\w\.-]+@[\w\.-]+\.[a-zA-Z]+' , driver.page_source) if email_matches: for email in email_matches: email_addresses.append(email) driver.quit() print (email_addresses)
运行效果如下,selenium 会自动打开浏览器,访问这两百多个页面
到这里我们就大功告成了,感谢大家的阅读。